
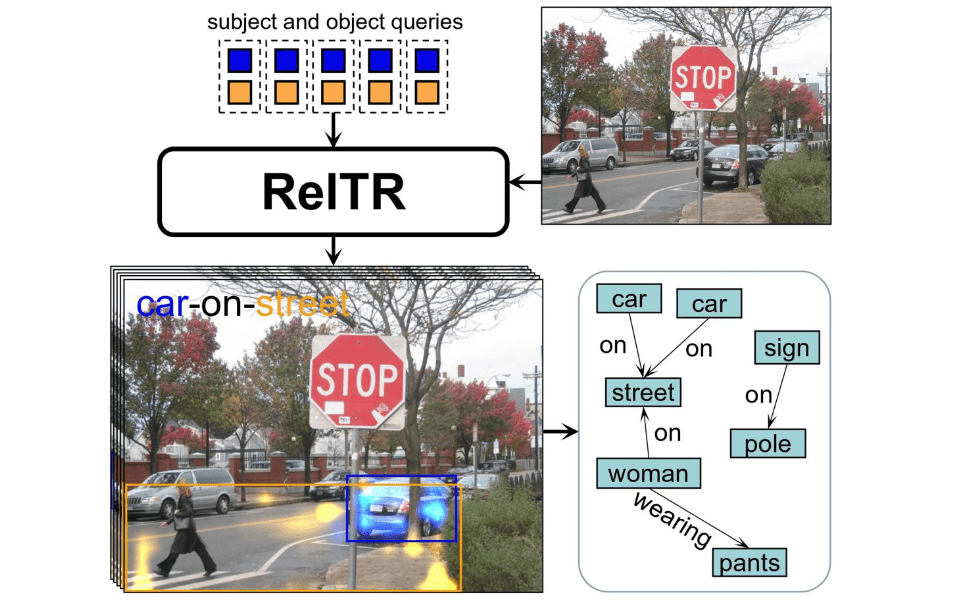
Der Forscher Michael Ying Yang von der Universität Twente hat eine bahnbrechende Methode entwickelt, um mithilfe von KI realistische und kohärente Bilder aus Textaufforderungen zu erzeugen. Der neue Ansatz, ReITR genannt, konzentriert sich auf die Erstellung von Szenegraphen, die für ein besseres Verständnis der visuellen Beziehungen zwischen Objekten durch KI entscheidend sind, schreibt die Universität in einer Pressemitteilung.
Diese innovative einstufige Methode sagt Subjekte, Objekte und ihre Beziehungen gleichzeitig voraus, was die Verarbeitungszeit im Vergleich zu herkömmlichen zweistufigen Ansätzen erheblich reduziert. Die in der Fachzeitschrift IEEE T-PAMI veröffentlichte Forschungsarbeit verspricht, die Bilderzeugung sowie die Wahrnehmung von autonomen Fahrzeugen und Robotern zu verbessern.
- ReITR (Relation Transformer for Scene Graph Generation) erzeugt mit Hilfe von KI realistische und kohärente Bilder aus textuellen Aufforderungen.
- ReITR konzentriert sich auf die Erstellung von Szenegraphen, die das Verständnis der KI für visuelle Beziehungen zwischen Objekten verbessern und die Verarbeitungszeit im Vergleich zu herkömmlichen zweistufigen Ansätzen erheblich reduzieren.
Ein Sprung nach vorn beim Verstehen von Szenen
Die künstliche Intelligenz hat große Fortschritte bei der Erzeugung von Bildern aus Textaufforderungen gemacht, aber die meisten generativen KI-Modelle zeichnen sich dadurch aus, dass sie Bilder von einzelnen Objekten und nicht von ganzen Szenen erzeugen. Der Mensch hingegen ist in der Lage, Beziehungen zwischen Objekten zu definieren, z. B. zu verstehen, dass ein Stuhl auf dem Boden steht oder ein Hund auf der Straße läuft. Um diese Lücke zu schließen, entwickelte Yang, Assistenzprofessor in der Scene Understanding Group der Fakultät für Geoinformationswissenschaften und Erdbeobachtung (ITC), eine neue Methode namens ReITR (Relation Transformer for Scene Graph Generation).
Dieser neue Ansatz konstruiert Szenegraphen aus Bildern, die als Blaupausen für die Erzeugung realistischer und kohärenter Bilder dienen. Durch die Verbesserung der Fähigkeit der künstlichen Intelligenz, visuelle Beziehungen zwischen Objekten zu erkennen und zu verstehen, verbessert ReITR nicht nur die Bilderzeugung, sondern unterstützt auch die Wahrnehmung von autonomen Fahrzeugen und Robotern, die ein genaues Verständnis der Szene benötigen, um zu navigieren und mit ihrer Umgebung zu interagieren.
Einstufige Methode für schnellere Verarbeitung
Herkömmliche Methoden zur grafischen Darstellung eines semantischen Verständnisses eines Bildes verwenden einen zweistufigen Ansatz, der langsam und ineffizient ist. In der ersten Stufe werden alle Objekte in einer Szene kartiert, während in der zweiten Stufe ein spezielles neuronales Netz alle möglichen Verbindungen durchgeht und sie mit der richtigen Beziehung kennzeichnet. Die Anzahl der Verbindungen, die bei dieser Methode verarbeitet werden müssen, steigt jedoch exponentiell mit der Anzahl der Objekte, was die Methode sehr zeitaufwändig macht.
ReITR hingegen benötigt nur einen einzigen Schritt, um das gleiche Ziel zu erreichen. Es sagt automatisch Subjekte, Objekte und ihre Beziehungen zur gleichen Zeit voraus, was die Verarbeitungszeit drastisch reduziert. Das Modell von ReITR untersucht die visuellen Merkmale von Objekten in einer Szene und konzentriert sich auf die wichtigsten Details zur Bestimmung ihrer Beziehungen. Es hebt wesentliche Bereiche hervor, in denen Objekte interagieren oder in Beziehung zueinander stehen, und nutzt diese Techniken und relativ wenige Trainingsdaten, um die wichtigsten Beziehungen zwischen verschiedenen Objekten zu ermitteln. Das Modell erstellt dann eine Beschreibung, wie die Objekte miteinander verbunden sind.
Praktische Anwendungen und zukünftige Entwicklungen
Die Fortschritte von ReITR beim Verstehen von Szenen haben das Potenzial, verschiedene Bereiche und Anwendungen zu beeinflussen. Der Durchbruch könnte beispielsweise autonomen Fahrzeugen und Robotern zugute kommen, die auf ein genaues Verständnis der Szene und Objekterkennung angewiesen sind, um zu navigieren und Entscheidungen zu treffen. Darüber hinaus könnte die Fähigkeit von ReITR, realistische und kohärente Bilder aus Textanweisungen zu erzeugen, in der Computergrafik, der virtuellen und erweiterten Realität und sogar bei der Entwicklung von Videospielen Anwendung finden.
ReITR stellt zwar einen bedeutenden Fortschritt dar, ist aber Teil einer breiteren Forschungslandschaft, die sich mit der Fähigkeit von KI zur Verarbeitung von 3D-Daten und zum Verständnis von Szenen befasst. Die TensorFlow 3D-Bibliothek von Google Research wurde beispielsweise entwickelt, um 3D-Fähigkeiten für tiefes Lernen in TensorFlow einzubringen und damit eine Technologie zum Verstehen von Szenen für maschinelle Lernsysteme wie autonome Autos und Roboter zu ermöglichen. Da die Forschung in diesem Bereich weiter voranschreitet, können wir weitere Innovationen und Anwendungen erwarten, die das Potenzial der KI für die Bilderzeugung und das Verstehen von Szenen nutzen.