
Onderzoeker Michael Ying Yang van Universiteit Twente heeft een baanbrekende methode ontwikkeld voor het genereren van realistische en samenhangende beelden van tekstuele aanwijzingen met behulp van AI. De nieuwe aanpak, ReITR, richt zich op het maken van scènegrafieken, die cruciaal zijn voor het verbeteren van AI’s begrip van visuele relaties tussen objecten, schrijft de universiteit in een persbericht.
Deze innovatieve eenstapsmethode voorspelt onderwerpen, objecten en hun relaties tegelijkertijd, waardoor de verwerkingstijd aanzienlijk wordt verkort in vergelijking met traditionele tweestapsbenaderingen. Het onderzoek, gepubliceerd in het wetenschappelijke tijdschrift IEEE T-PAMI, belooft het genereren van beelden en de perceptie van autonome voertuigen en robots te verbeteren.
- ReITR (Relation Transformer for Scene Graph Generation) genereert realistische en samenhangende beelden van tekstuele aanwijzingen met behulp van AI.
- ReITR richt zich op het maken van scènegrafieken, die het begrip van AI van visuele relaties tussen objecten verbeteren en de verwerkingstijd aanzienlijk verkorten in vergelijking met traditionele tweefasenbenaderingen.
Een sprong voorwaarts in het begrijpen van scènes
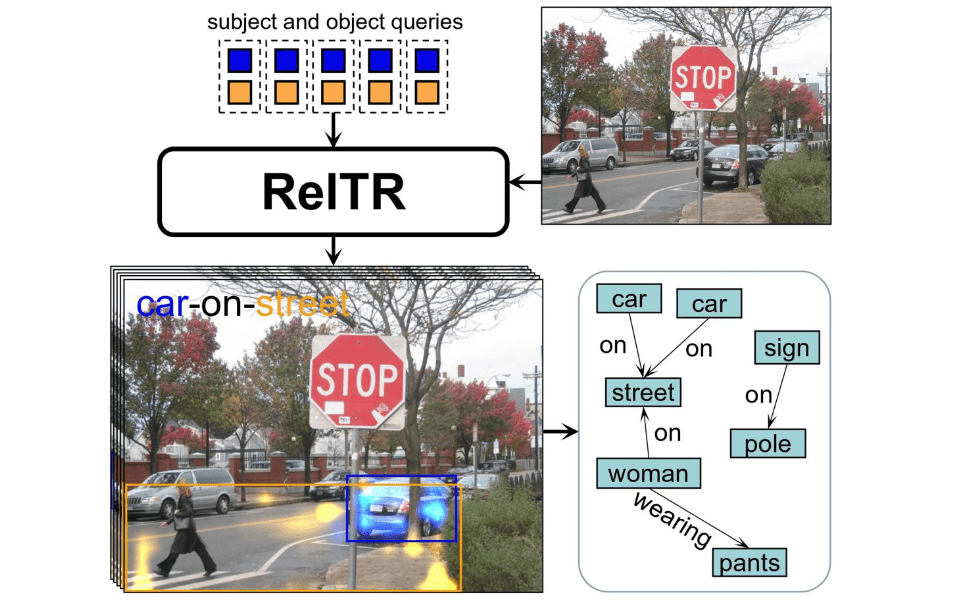
Kunstmatige intelligentie heeft aanzienlijke vooruitgang geboekt in het genereren van afbeeldingen op basis van tekstuele aanwijzingen, maar de meeste generatieve AI-modellen blinken uit in het maken van afbeeldingen van afzonderlijke objecten in plaats van complete scènes. Mensen daarentegen zijn bedreven in het definiëren van relaties tussen objecten, zoals begrijpen dat een stoel op de grond staat of dat er een hond op straat loopt. Om deze kloof te overbruggen, ontwikkelde Yang, assistent-professor bij de Scene Understanding Group van de faculteit Geo-Information Science and Earth Observation (ITC), een nieuwe methode genaamd ReITR (Relation Transformer for Scene Graph Generation).
Deze nieuwe benadering construeert scènegrafieken uit beelden, die dienen als blauwdrukken voor het genereren van realistische en coherente beelden. Door het vermogen van AI om visuele relaties tussen objecten te detecteren en te begrijpen te verbeteren, verbetert ReITR niet alleen het genereren van beelden, maar helpt het ook bij de perceptie van autonome voertuigen en robots, die een nauwkeurig begrip van de scène nodig hebben om te navigeren en te communiceren met hun omgeving.

Eenstapsmethode voor snellere verwerking
Traditionele methoden om een semantisch begrip van een afbeelding in kaart te brengen gebruiken een tweefasenaanpak, die traag en inefficiënt is. De eerste fase brengt alle objecten in een scène in kaart, terwijl de tweede fase een specifiek neuraal netwerk gebruikt om alle mogelijke verbindingen te doorlopen en ze te labelen met de juiste relatie. Het aantal verbindingen dat deze methode moet verwerken neemt echter exponentieel toe met het aantal objecten, waardoor het tijdrovend wordt.
ReITR daarentegen heeft slechts één stap nodig om hetzelfde doel te bereiken. Het voorspelt automatisch onderwerpen, objecten en hun relaties tegelijkertijd, waardoor de verwerkingstijd drastisch wordt verkort. Het model van ReITR onderzoekt de visuele kenmerken van objecten in een scène en richt zich op de meest relevante details voor het bepalen van hun relaties. Het markeert essentiële gebieden waar objecten op elkaar inwerken of met elkaar in verband staan en gebruikt deze technieken en relatief weinig trainingsgegevens om de meest cruciale relaties tussen verschillende objecten te identificeren. Het model genereert vervolgens een beschrijving van hoe de objecten met elkaar verbonden zijn.
Praktische toepassingen en toekomstige ontwikkelingen
De vooruitgang van ReITR op het gebied van het begrijpen van scènes heeft het potentieel om verschillende gebieden en toepassingen te beïnvloeden. De doorbraak zou bijvoorbeeld ten goede kunnen komen aan autonome voertuigen en robots, die afhankelijk zijn van nauwkeurig inzicht in scènes en objectherkenning om te navigeren en beslissingen te nemen. Bovendien zou het vermogen van ReITR om realistische en samenhangende beelden te genereren op basis van tekstuele aanwijzingen toepassingen kunnen vinden in computergraphics, virtuele en augmented reality en zelfs het ontwerpen van videogames.
Hoewel ReITR een belangrijke stap voorwaarts is, maakt het deel uit van een breder landschap van onderzoek naar het vermogen van AI om 3D-gegevens te verwerken en scènes te begrijpen. De TensorFlow 3D-bibliotheek van Google Research is bijvoorbeeld ontworpen om 3D deep learning-mogelijkheden in TensorFlow te brengen, waardoor technologie voor het begrijpen van scènes mogelijk wordt voor machine-leersystemen zoals autonome auto’s en robots. Naarmate het onderzoek op dit gebied zich blijft ontwikkelen, kunnen we meer innovaties en toepassingen verwachten die gebruik maken van het potentieel van AI voor het genereren van beelden en het begrijpen van scènes.